Data Science para marketing
Creado por Nicolás Labbé
Limpieza y Preparación de datos
Manipulación de datos
Ahora que hemos deconstruido la estructura del DataFrame de pandas hasta sus fundamentos, el resto de las tareas de organización, es decir, crear nuevos DataFrames, seleccionar o dividir un DataFrame en sus partes, filtrar DataFrames por valores, unir diferentes DataFrames, etc., serán muy intuitivas. Comencemos seleccionando y filtrando en la siguiente sección.
Selección y filtrado en Pandas
Si quisiera acceder a una celda específica en una hoja de cálculo, lo haría utilizando el formato habitual (nombre de columna, nombre de fila). Por ejemplo, al llamar a la celda A63, A se refiere a la columna y 63 a la fila. Los datos se almacenan de forma similar en Pandas, pero como (nombre de fila, nombre de columna), y podemos usar la misma convención para acceder a las celdas en un DataFrame.
Por ejemplo, observa el siguiente DataFrame. La columna "viewers" es el índice del DataFrame:
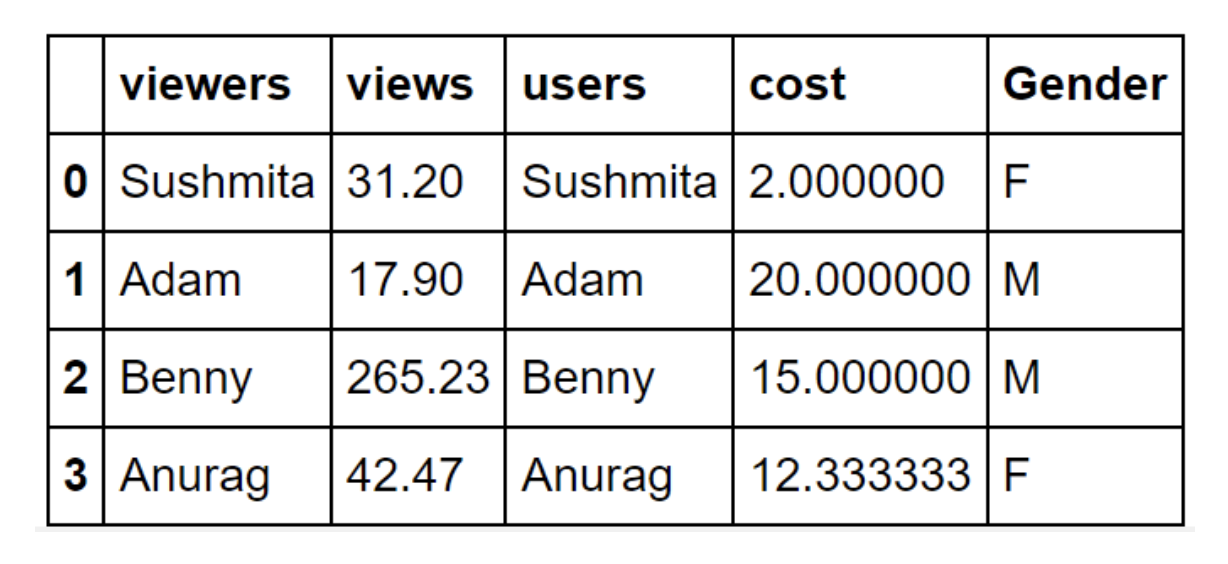 Figura 9.1 - Ejemplo de DataFrame
Figura 9.1 - Ejemplo de DataFrame
Para calcular el coste de adquisición de Adam y Anurag, junto con sus visitas, podemos usar el siguiente código. Aquí, Adam y Anurag son las filas, y el coste, junto con las visitas, son las columnas:
df.loc[['Adam','Anurag'],['cost','views']]
Ejecutar el comando anterior generará el siguiente resultado:
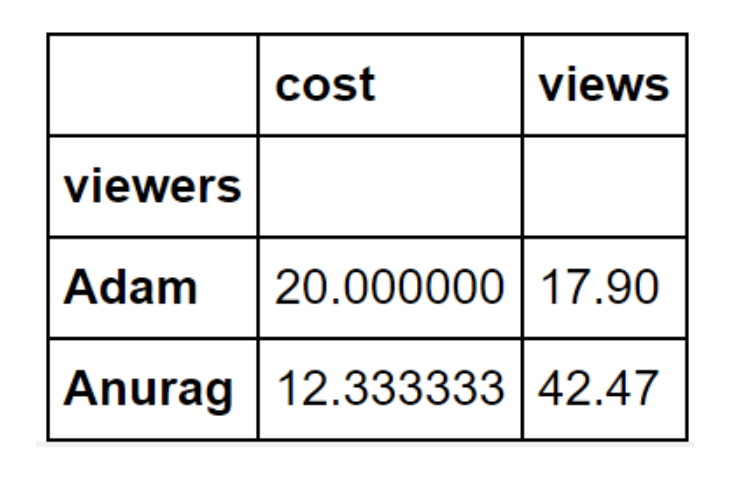 Figura 9.2 - Uso de la función loc
Figura 9.2 - Uso de la función loc
Si necesita acceder a más de una celda, como un subconjunto de algunas filas y columnas del DataFrame, o cambiar el orden de visualización de algunas columnas en el DataFrame, puede utilizar la sintaxis que aparece en la siguiente tabla:
| Operación | Sintaxis | Resultado |
|---|---|---|
| Seleccionar una columna | df[col] | Serie |
| Seleccionar múltiples columnas | df[[col1, col2, ...]] | DataFrame |
| Seleccionar una fila por etiqueta | df.loc[label] | Serie |
| Seleccionar una fila por ubicación entera | df.iloc[loc] | Serie |
| Rebanar filas | df[start_idx:end_idx] | DataFrame |
| Seleccionar múltiples filas por vector booleano | df[bool_vec] | DataFrame |
Creación de DataFrames en Python
Supongamos que ha cargado datos de campaña en un DataFrame. En la columna de ingresos, observa que las cifras no están en las monedas deseadas. Para convertir las cifras de ingresos a otras monedas, puede que necesite crear un DataFrame de prueba con tipos de cambio que se mantengan constantes durante el cálculo de ingresos.
Hay dos maneras de crear estos DataFrames de prueba:
- Creando DataFrames completamente nuevos
- Duplicando o tomando una parte de un DataFrame existente
Creación de nuevos DataFrames
Normalmente se usa la función DataFrame para crear un DataFrame completamente nuevo. Esta función convierte directamente un objeto de Python en un DataFrame de Pandas. En general, la función DataFrame funciona con cualquier colección iterable de datos, como diccionarios y listas. También se puede pasar una colección vacía o una colección singleton.
Por ejemplo, obtendrá el mismo DataFrame a través de cualquiera de las siguientes líneas de código:
import pandas as pd
df = pd.DataFrame(
{'Currency': pd.Series(['USD','EUR','GBP']),
'ValueInINR': pd.Series([70, 89, 99])}
)
df = pd.DataFrame.from_dict(
{'Currency': ['USD','EUR','GBP'],
'ValueInINR':[70, 89, 99]}
)
df.head()
Ejecutar el comando de cualquiera de estas dos maneras generará el siguiente resultado:
| Currency | ValueInINR | |
|---|---|---|
| 0 | USD | 70 |
| 1 | EUR | 89 |
| 2 | GBP | 99 |
Duplicar o segmentar un DataFrame ya existente
La segunda forma de crear un DataFrame es copiar un DataFrame ya existente. Lo primero que se podría intuir sería algo como obj1 = obj2. Sin embargo, dado que ambos objetos comparten una referencia al mismo objeto en memoria, al cambiar obj2 también se cambiará obj1, y viceversa.
Puedes solucionar esto con una función de la biblioteca estándar llamada deepcopy. Esta función permite al usuario revisar recursivamente los objetos a los que apuntan las referencias y crear objetos completamente nuevos.
Por lo tanto, si quieres copiar un DataFrame ya existente y no quieres que se vea afectado por las modificaciones del nuevo, necesitas usar la función deepcopy. También puedes segmentar el DataFrame ya existente y pasarlo a la función, y se considerará un nuevo DataFrame.
Por ejemplo, el siguiente fragmento de código copiará recursivamente todo el contenido de df a df1. Ahora, los cambios que realice en df1 no afectarán a df:
import pandas
import copy
df1 = df.copy(deep=True)
df1.head()
El contenido de df1 será el mismo que df:
| Currency | ValueInINR | |
|---|---|---|
| 0 | USD | 70 |
| 1 | EUR | 89 |
| 2 | GBP | 99 |
Adición y eliminación de atributos y observaciones
Pandas ofrece las siguientes funciones para agregar y eliminar filas (observaciones) y columnas (atributos):
- :
- df.append(df2): Este método añade valores del DataFrame df2 al final del DataFrame df donde las columnas de df2 coincidan con las de df.
- df.drop(labels, axis): Este método elimina las filas o columnas especificadas por las etiquetas y el eje correspondiente, o las especificadas directamente por el índice o los nombres de columna.
Añade una nueva columna, col, al DataFrame, df, creando una nueva columna con valores de la serie, s.
import pandas as pd
df['col'] = pd.Series([1, 2, 3])
| Currency | ValueInINR | col | |
|---|---|---|---|
| 0 | USD | 70 | 1 |
| 1 | EUR | 89 | 2 |
| 2 | GBP | 99 | 3 |
El método assign() agrega una nueva columna a un DataFrame existente.
import pandas as pd
data = {
"age": [16, 14, 10],
"qualified": [True, True, True]
}
df = pd.DataFrame(data)
df = df.assign(name = ["Emil", "Tobias", "Linus"])
df.head()
| age | qualified | name | |
|---|---|---|---|
| 0 | 16 | True | Emil |
| 1 | 14 | True | Tobias |
| 2 | 10 | True | Linus |
El método concat() concatenar objetos pandas a lo largo de un eje particular..
import pandas as pd
df1 = pd.DataFrame([['a', 1], ['b', 2]], columns=['letter', 'number'])
df1
df2 = pd.DataFrame([['c', 3], ['d', 4]], columns=['letter', 'number'])
df2
pd.concat([df1, df2])
| letter | number | |
|---|---|---|
| 0 | a | 1 |
| 1 | b | 2 |
| 0 | c | 3 |
| 1 | d | 4 |
El método drop() elimina las filas o columnas especificadas por las etiquetas y el eje correspondiente, o aquellas especificadas por el índice o los nombres de las columnas directamente.
import pandas as pd
df = pd.DataFrame(
{'Currency': pd.Series(['USD','EUR','GBP']),
'ValueInINR': pd.Series([70, 89, 99])}
)
df=df.drop(['Currency'],axis=1)
df
| ValueInINR | |
|---|---|
| 0 | 70 |
| 1 | 89 |
| 2 | 99 |