Data Science para marketing
Creado por Nicolás Labbé
Limpieza y Preparación de datos
Pandas
Pandas es una biblioteca de software escrita en Python y constituye el componente básico para la manipulación y el análisis de datos. Ofrece una colección de estructuras de datos y herramientas de análisis de alto rendimiento, fáciles de usar e intuitivas, de gran utilidad tanto para analistas de marketing como para científicos de datos.
Puedes ejecutar el siguiente comando en tu aplicación de terminal o en el símbolo del sistema para instalar la biblioteca:
pip install pandas
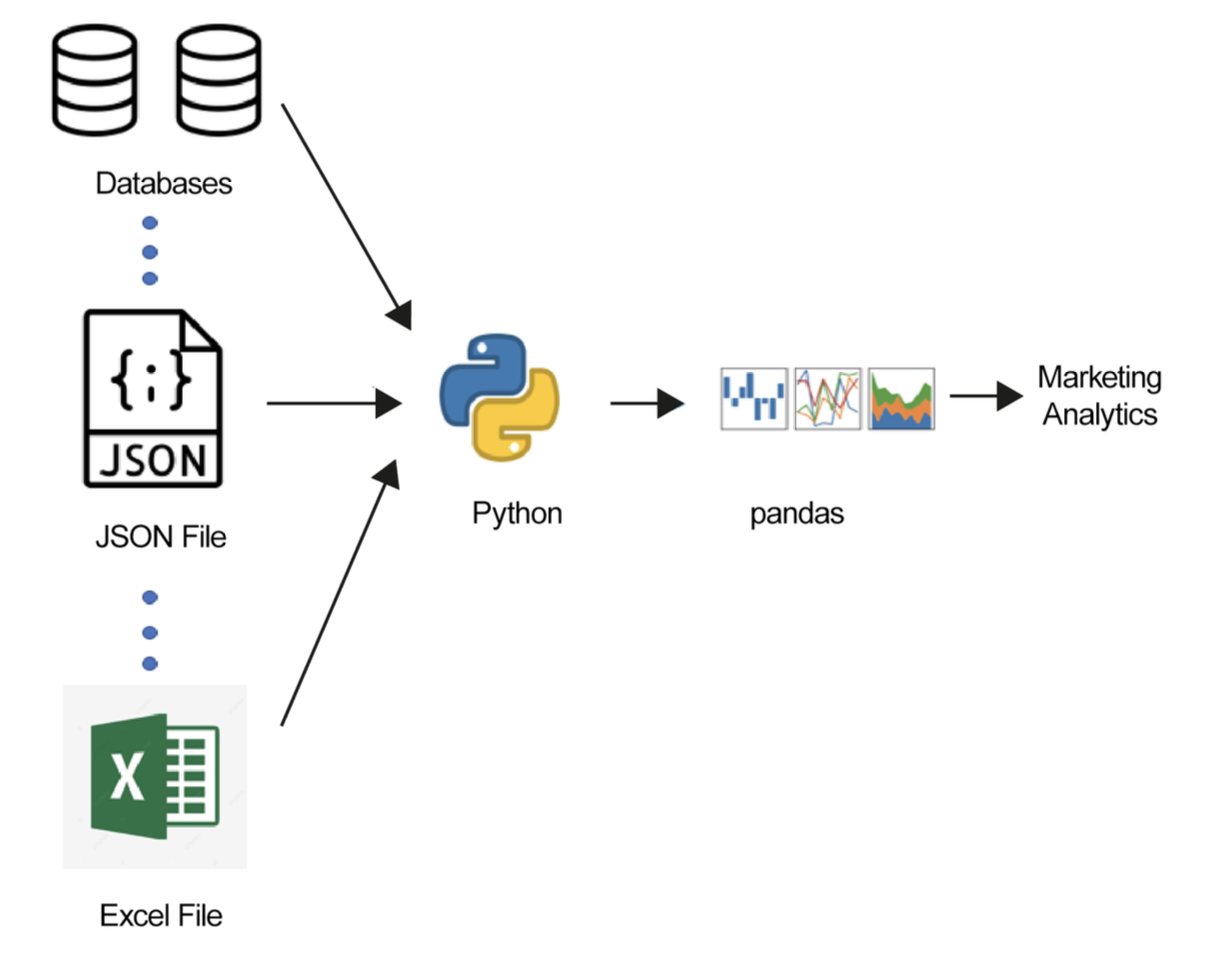 Figura 1.5 - Modelo de datos para estructurar diferentes tipos de datos
Figura 1.5 - Modelo de datos para estructurar diferentes tipos de datos
Al trabajar con pandas, trabajarás con sus dos tipos de objetos principales:
- DataFrames
- Series
DataFrame
Esta es la estructura tabular fundamental que almacena datos en filas y columnas (como una hoja de cálculo). Al analizar datos, se pueden aplicar funciones y operaciones directamente a los DataFrames.
Series
Se refiere a una sola columna del DataFrame. Las series se suman para formar un DataFrame. Se puede acceder a los valores mediante su índice, que se asigna automáticamente al definir un DataFrame.
En el siguiente diagrama, la columna de usuarios anotada con 2 es una serie, y las columnas de espectadores, vistas, usuarios y costos, junto con el índice, forman un DataFrame (anotado con 1):
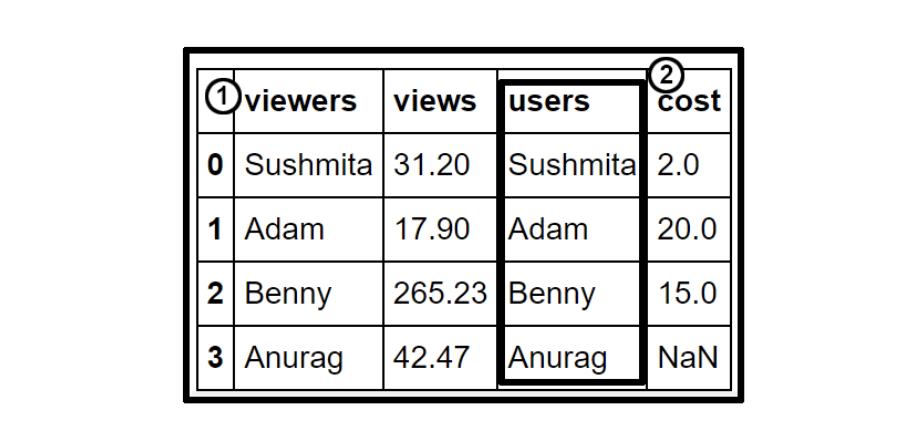 Figura 1.6 - Un ejemplo de DataFrame y serie de pandas
Figura 1.6 - Un ejemplo de DataFrame y serie de pandas
Ahora que tienes una breve comprensión de qué son los objetos de pandas, echemos un vistazo a algunas de las funciones que puede utilizar para importar y exportar datos en pandas.
Importación y exportación de datos con DataFrames de Pandas
Cada equipo de marketing puede tener su propia fuente de datos preferida para su caso de uso específico. Los equipos que gestionan una gran cantidad de datos de clientes, como datos demográficos e historial de compras, preferirían una base de datos como MySQL u Oracle, mientras que los equipos que gestionan mucho texto podrían preferir JSON, CSV o XML.
Debido al uso de múltiples fuentes de datos, terminamos teniendo una gran variedad de archivos. En estos casos, la biblioteca de Pandas nos ayuda, ya que proporciona diversas API (interfaces de programación de aplicaciones) que permiten leer múltiples tipos de datos en un DataFrame de Pandas. Algunas de las API más utilizadas se muestran a continuación:
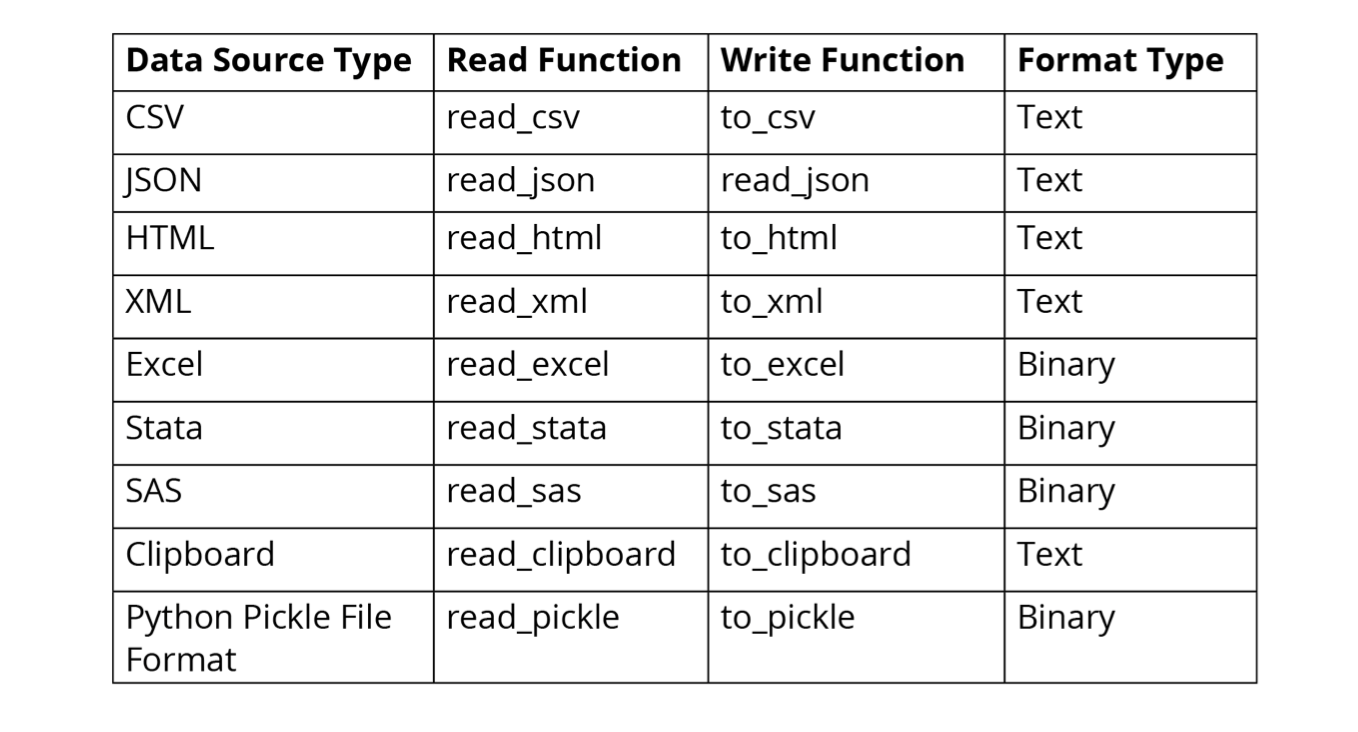 Figura 1.7 - Formas de importar y exportar diferentes tipos de datos con Pandas DataFrames
Figura 1.7 - Formas de importar y exportar diferentes tipos de datos con Pandas DataFrames
Supongamos que desea leer un archivo CSV. Primero deberá importar la biblioteca de Pandas como se indica a continuación:
import pandas as pd
Luego, ejecutará el siguiente código para almacenar el archivo CSV en un DataFrame llamado df (df es una variable):
df = pd.read_csv("sales.csv")
En la línea anterior, tenemos sales.csv, el archivo que se importará. Este comando debería funcionar si su Jupyter Notebook (o proceso de Python) se ejecuta desde el mismo directorio donde está almacenado el archivo. Si el archivo se almacenó en otra ruta, deberá especificar la ruta exacta.
En Windows, por ejemplo, la ruta se especifica de la siguiente manera:
df = pd.read_csv(r"C:\Users\abhis\Documents\sales.csv")
Debes tener en cuenta que añadimos "r" antes de la ruta para evitar cualquier carácter especial. Al trabajar con e importar diversos archivos de datos en los ejercicios y actividades de este libro, le recordaremos con frecuencia que preste atención a la ruta del archivo CSV.
Al cargar datos, Pandas también proporciona parámetros adicionales que se pueden pasar a la función de lectura para que se puedan cargar los datos como se desee. Algunos de estos parámetros se proporcionan aquí. Tenga en cuenta que la mayoría son opcionales. Cabe destacar que el valor predeterminado del índice en un DataFrame empieza en 0:
pandas.read_csvPor ejemplo, si desea importar un archivo CSV a un DataFrame, df, con las siguientes condiciones:
- La primera fila del archivo debe ser el encabezado.
- Solo debe importar las primeras 100 filas al archivo.
- Solo debe importar las primeras 3 columnas.
El código correspondiente a las condiciones anteriores sería el siguiente:
df = pd.read_csv("sales.csv",header=1,nrows=100,usecols=[0,1,2])
💡 Nota
Existen parámetros específicos similares para casi todas las funciones integradas en Pandas. Puede encontrar más información sobre ellos en la documentación de Pandas.
Una vez importados los datos, debes verificar su correcta importación. En la siguiente sección, veremos cómo hacerlo.
Visualización e inspección de datos en DataFrames
Una vez que hayas leído correctamente un DataFrame con la biblioteca de Pandas, debe inspeccionar los datos para comprobar si el atributo correcto ha recibido el valor correcto. Puedes usar varias funciones integradas de Pandas para ello.
La forma más común de inspeccionar los datos cargados es mediante el comando head(). De forma predeterminada, este comando mostrará las primeras cinco filas del DataFrame. A continuación, se muestra un ejemplo del comando utilizado en un DataFrame llamado df:
df.head()
De forma similar, para mostrar las últimas cinco filas, puedes usar el comando df.tail(). En lugar de las cinco filas predeterminadas, puede especificar el número de filas que desea mostrar. Por ejemplo, el comando df.head(11) mostrará las primeras 11 filas.
Aquí se muestra el uso completo de estos dos comandos, junto con algunos otros comandos útiles al examinar datos.
df.shapedevolverá las dimensiones de un DataFrame (número de filas y columnas).df.dtypesdevolverá el tipo de dato en cada columna del DataFrame de pandas (como float, object, int64, etc.).df.info()resumirá el DataFrame e imprimirá su tamaño, el tipo de valores y el número de valores no nulos.
Hasta ahora, has aprendido sobre las diferentes funciones que se pueden usar en DataFrames. En el primer ejercicio, practicarás el uso de estas funciones para importar un archivo JSON a un DataFrame y, posteriormente, para inspeccionar los datos.
Ejercicio 1.01: Carga de datos almacenados en un archivo JSON
El equipo técnico de su empresa ha estado probando la versión web de su aplicación de compras insignia. A algunos usuarios fieles que se ofrecieron como voluntarios para probar el sitio web se les pidió que enviaran sus datos mediante un formulario en línea. El formulario recogió algunos datos útiles (como la edad, los ingresos, etc.) y otros menos útiles (como el color de ojos). Posteriormente, el equipo técnico probó su nuevo módulo de página de perfil, con el que se recogieron algunos datos adicionales. Todos estos datos se almacenaron en un archivo JSON llamado user_info.json, que el equipo técnico les envió para su validación.Tu objetivo es importar este archivo JSON a Pandas e informar al equipo técnico de las respuestas a las siguientes preguntas para que puedan añadir más módulos al sitio web:
- ¿Se cargan correctamente los datos?
- ¿Faltan valores en alguna columna?
- ¿Cuáles son los tipos de datos de todas las columnas?
- ¿Cuántas filas y columnas hay en el conjunto de datos?
Ejercicio 1.02: Carga de datos de múltiples fuentes
Trabajas para una empresa que utiliza Facebook para sus campañas de marketing. El archivo data.csv contiene las visualizaciones y los "me gusta" de 100 publicaciones diferentes en Facebook utilizadas para una campaña de marketing. El equipo también utiliza datos históricos de ventas para obtener información. El archivo sales.csv contiene datos históricos de ventas registrados en un archivo CSV relacionados con las compras de diferentes clientes en tiendas físicas en los últimos años.Tu objetivo es leer los archivos en DataFrames de Pandas y comprobar lo siguiente:
- Si alguno de los conjuntos de datos contiene valores nulos o faltantes.
- Si los datos están almacenados en las columnas correctas y si los nombres de las columnas correspondientes son coherentes (es decir, si los nombres de las columnas indican correctamente el tipo de información almacenada en las filas).
Estructura de un DataFrame y una Serie de Pandas
Puede que no estés seguro de qué estructura de datos usar para almacenar la información que proviene de diferentes equipos de marketing. Por experiencia, sabe que algunos elementos de sus datos tendrán valores faltantes.
Además, espera que dos equipos diferentes recopilen los mismos datos, pero los categoricen de forma diferente. Es decir, en lugar de índices numéricos (0-10), podrían usar etiquetas personalizadas para acceder a valores específicos. Pandas proporciona estructuras de datos que ayudan a almacenar y trabajar con dichos datos. Una de estas estructuras de datos se denomina serie de Pandas.
Una serie de Pandas no es más que una matriz indexada de NumPy. Para crear una serie de Pandas, solo necesita crear una matriz y asignarle un índice. Si crea una serie sin índice, se creará un índice numérico predeterminado que comienza en 0 y continúa a lo largo de la serie, como se muestra en el siguiente diagrama:
 Figura 1.8 - Ejemplo de Serie de pandas.
Figura 1.8 - Ejemplo de Serie de pandas.
💡 Nota
Como una serie sigue siendo un array NumPy, todas las funciones que funcionan en un array NumPy funcionan igual en una serie de Pandas. Para obtener más información sobre las funciones, consulte el siguiente enlace: https://pandas.pydata.org/pandas-docs/stable/reference/series.html.
A medida que crece su campaña, también crece el número de series. Con ello, surgen nuevos requisitos. Ahora, desea poder realizar operaciones como la concatenación en entradas específicas de varias series a la vez.
Sin embargo, para acceder a los valores, estas diferentes series deben compartir el mismo índice. Y ahí es precisamente donde entran en juego los DataFrames. Un DataFrame de Pandas es simplemente un diccionario con los nombres de las columnas como claves y los valores como diferentes series de Pandas, unidos por el índice.
Un DataFrame se crea cuando diferentes columnas (que no son más que series) como estas se unen mediante el índice:
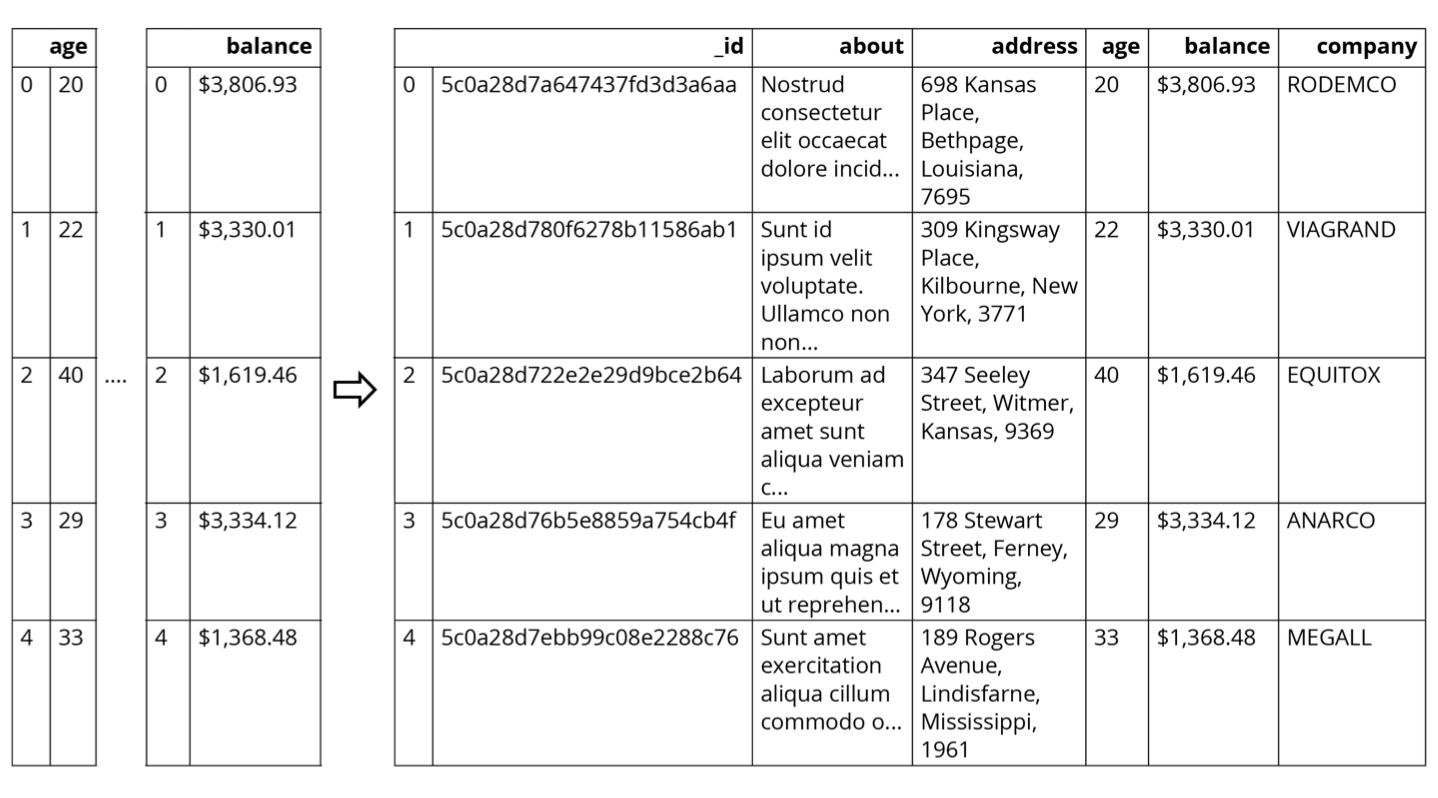 Figura 1.9 - Las series unidas por el mismo índice crean un DataFrame de pandas.
Figura 1.9 - Las series unidas por el mismo índice crean un DataFrame de pandas.
En la captura de pantalla anterior, verás los números del 0 al 4 a la izquierda de la columna de edad. Estos son los índices. Las columnas de edad, saldo, _id, información sobre y dirección, junto con otras, son series y, juntas, forman un DataFrame.
Esta forma de almacenar datos facilita enormemente la realización de las operaciones necesarias con los datos deseados. Puedes elegir fácilmente la serie que desea modificar seleccionando una columna y separando directamente los índices según su valor. También puedes agrupar índices con valores similares en una columna y ver cómo cambian los valores en otras columnas.
Pandas también permite aplicar operaciones tanto a filas como a columnas de un DataFrame. Puedes elegir cuál aplicar especificando el eje, donde 0 se refiere a las filas y 1 a las columnas.
Por ejemplo, si quisieras aplicar la función suma a todas las filas de la columna de saldo del DataFrame, usaría el siguiente código:
df['balance'].sum(axis=0)
En la siguiente captura de pantalla, al especificar axis=0, puedes aplicar una función (como suma) en todas las filas de una columna en particular:
Figura 1.10 - Entendiendo axis=0 y axis=1 en pandas.
Al especificar axis=1, puedes aplicar una función a una fila que abarque todas las columnas. En la siguiente sección, aprenderás a usar Pandas para manipular datos sin procesar y extraer información útil de ellos.