Data Science para marketing
Creado por Nicolás Labbé
Limpieza y Preparación de datos
Introducción
En esta unidad aprenderás:
- Habilidades necesarias para procesar y limpiar datos y prepararlos eficazmente para su posterior análisis.
- A leer e importar datos de varios formatos de archivo, incluyendo JSON y CSV, a un DataFrame.
- A segmentar, agregar y filtrar en DataFrames.
Al finalizar esta unidad, habrás consolidado tus habilidades de limpieza de datos aprendiendo a unir DataFrames, gestionar valores faltantes e incluso combinar datos de diversas fuentes.
“Como te gustó este artista, también te gustará su nuevo álbum.”
“Los clientes que compraron pan también compraron mantequilla.”
“1000 personas cerca de ti también pidieron este producto.”
Diariamente, recomendaciones como estas influyen en las decisiones de compra de los clientes, ayudándoles a descubrir nuevos productos. Estas recomendaciones son posibles gracias a las técnicas de ciencia de datos que aprovechan los datos para crear modelos complejos, realizar tareas sofisticadas y obtener información valiosa sobre los clientes con gran precisión.
Si bien el uso de los principios de la ciencia de datos en el análisis de marketing es una estrategia probada, rentable y eficiente, muchas empresas aún no aprovechan al máximo estas técnicas. Existe una gran brecha entre el uso posible y el real de estas técnicas.
Comenzaremos aprendiendo a limpiar y preparar datos. Los datos sin procesar de fuentes externas no se pueden utilizar directamente; deben analizarse, estructurarse y filtrarse antes de poder seguir utilizándose.
En este capítulo, aprenderá a manipular filas y columnas, y a aplicar transformaciones a los datos para garantizar que tenga los datos correctos con los atributos adecuados. Esta es una habilidad esencial en el arsenal de un analista de datos, ya que, de lo contrario, el resultado de su análisis se basará en datos incorrectos, convirtiéndose en un ejemplo clásico de "basura que entra, basura que sale".



Pero antes de empezar a trabajar con los datos, es importante comprender su naturaleza; en otras palabras, los diferentes tipos de datos con los que trabajará.
Tipos de conjuntos y modelos de datos
Al crear una solución analítica, lo primero que debe hacer es crear un modelo de datos. Un modelo de datos es una descripción general de las fuentes de datos que utilizará, sus relaciones con otras fuentes, dónde se obtendrán exactamente los datos de una fuente específica y en qué formato (por ejemplo, un archivo de Excel, una base de datos o un JSON de una fuente de internet).
Un modelo de datos puede contener datos de los tres tipos siguientes:
- Datos estructurados
- Datos semi-estructurados
- Datos no estructurados
Datos Estructurados
Los datos se organizan en una tabla plana, con el valor correcto correspondiente al atributo correcto. Existe una columna única, conocida como índice, para un acceso fácil y rápido a los datos, y no hay columnas duplicadas.
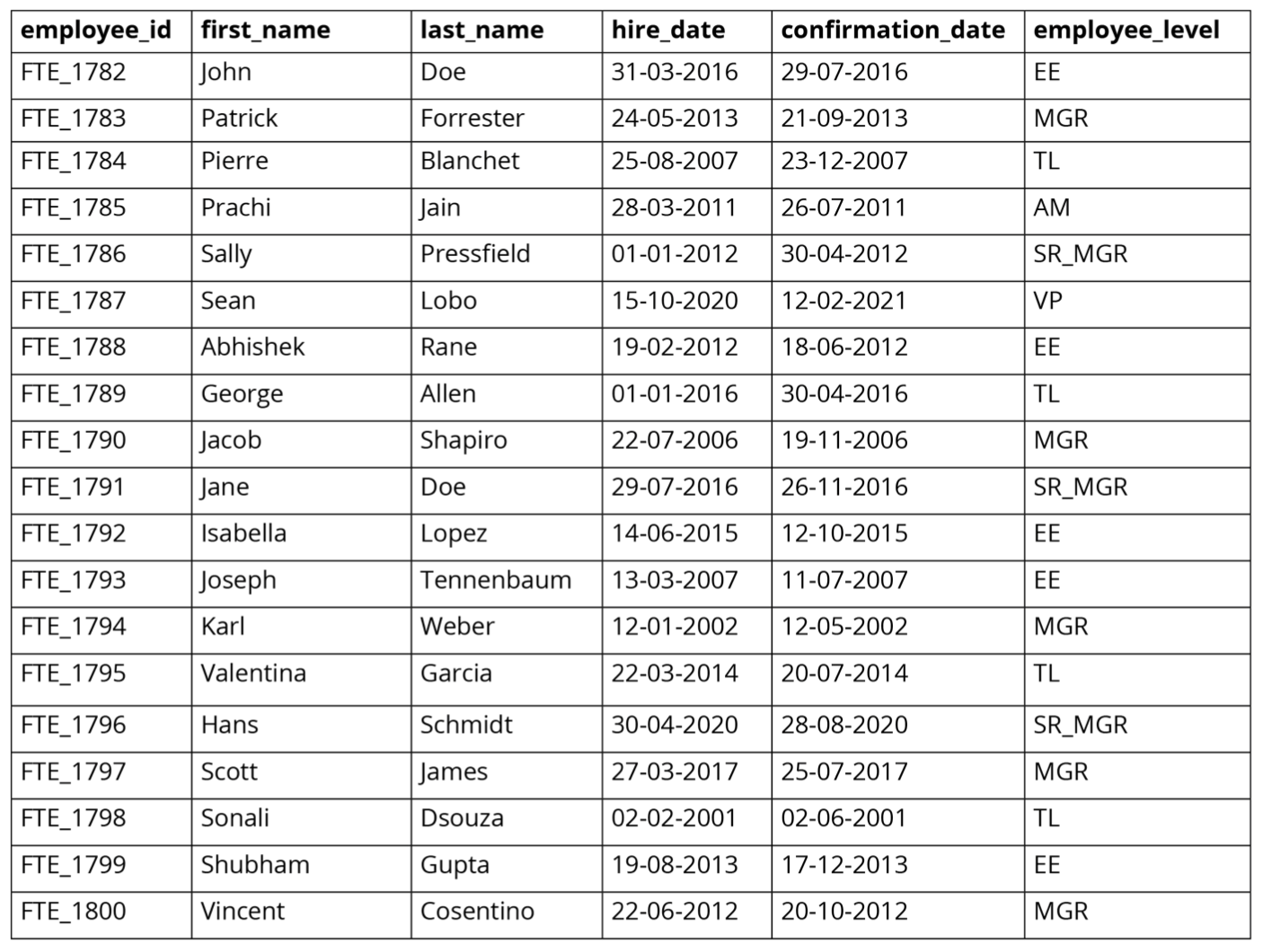 Figura 1.1 - Datos en una tabla MySQL
Figura 1.1 - Datos en una tabla MySQL
Por ejemplo, en la Figura 1.1, la columna única es "employee_id". Con los datos de esta columna, se pueden ejecutar consultas SQL y acceder rápidamente a los datos en una fila y columna específicas del conjunto de datos.
Además, no hay filas vacías, entradas faltantes ni columnas duplicadas, lo que facilita enormemente el trabajo con este conjunto de datos. Lo que hace que los datos estructurados sean tan comunes y fáciles de analizar es que se almacenan en un formato tabular estandarizado que facilita y programa la adición, actualización, eliminación y actualización de entradas.
Datos semiestructurados
Son datos que no tienen una estructura rígida, pero que sí contienen algunos elementos estructurales. Se organizan mediante etiquetas y metadatos, que permiten agruparlos y crear jerarquías.
No encontrarás datos semiestructurados almacenados en una jerarquía tabular estricta como la que se muestra en la Figura 1.1. Sin embargo, sí contarán con sus propias jerarquías que agrupan sus elementos y establecen una relación entre ellos.
 Figura 1.2 - Datos en un archivo JSON
Figura 1.2 - Datos en un archivo JSON
Datos no estructurados
Los datos no estructurados pueden no ser tabulares, e incluso si lo son, el número de atributos o columnas por observación puede ser completamente arbitrario. Los mismos datos podrían representarse de diferentes maneras, y los atributos podrían no coincidir entre sí, con valores que se filtran a otras partes.
Por ejemplo, piensa en las reseñas de varios productos almacenadas en filas de una hoja de Excel o en un volcado de los últimos tuits del perfil de Twitter de una empresa. Solo podemos buscar palabras clave específicas en esos datos, pero no podemos almacenarlos en una base de datos relacional ni establecer una jerarquía concreta entre los diferentes elementos o filas. Los datos no estructurados pueden almacenarse como archivos de texto, archivos CSV, archivos de Excel, imágenes y clips de audio.
Los datos de marketing, tradicionalmente, comprenden los tres tipos de datos mencionados anteriormente. Inicialmente, la mayoría de los puntos de datos provienen de diferentes fuentes. Esto conlleva diferentes implicaciones, como que los valores de un campo puedan tener longitudes diferentes, que el valor de un campo no coincida con el de otros debido a nombres de campo diferentes, y que algunas filas puedan tener valores faltantes en algunos campos.
Pronto aprenderás a abordar eficazmente estos problemas con sus datos usando Python. El siguiente diagrama ilustra el aspecto de un modelo de datos para el análisis de marketing. El modelo de datos comprende todo tipo de datos: datos estructurados como bases de datos (arriba), datos semiestructurados como JSON (centro) y datos no estructurados como archivos de Excel (abajo).
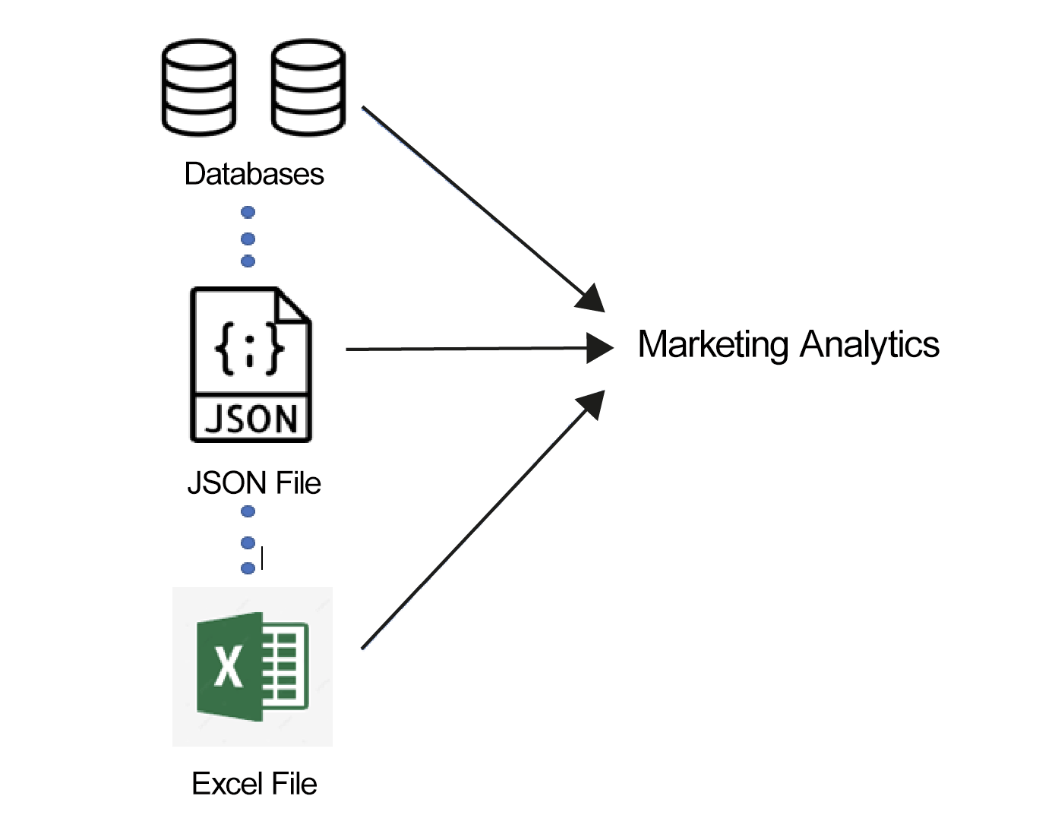 Figura 1.3 - Modelo de datos para análisis de marketing
Figura 1.3 - Modelo de datos para análisis de marketing
A medida que el modelo de datos se vuelve complejo, aumenta la probabilidad de tener datos erróneos. Por ejemplo, un analista de marketing que trabaja con los datos demográficos de un cliente puede interpretar erróneamente la edad del cliente como una cadena de texto en lugar de un número entero.
En tales situaciones, el análisis se descontrolaría, ya que el analista no puede realizar ninguna función de agregación, como calcular la edad promedio de un cliente.
Este tipo de situaciones se pueden solucionar mediante una verificación adecuada de la calidad de los datos para garantizar que los datos seleccionados para un análisis posterior sean del tipo correcto.
Aquí es donde entran en juego lenguajes de programación como Python. Python es un lenguaje de programación general y multipropósito que se integra con prácticamente todas las plataformas y ayuda a automatizar la producción y el análisis de datos.
Además de comprender patrones y proporcionar al menos una estructura básica a los datos, Python fuerza al modelo de datos a aceptar el valor correcto para el atributo. El siguiente diagrama ilustra cómo la mayoría de los análisis de marketing actuales estructuran diferentes tipos de datos pasándolos a través de scripts para que sean al menos semiestructurados:
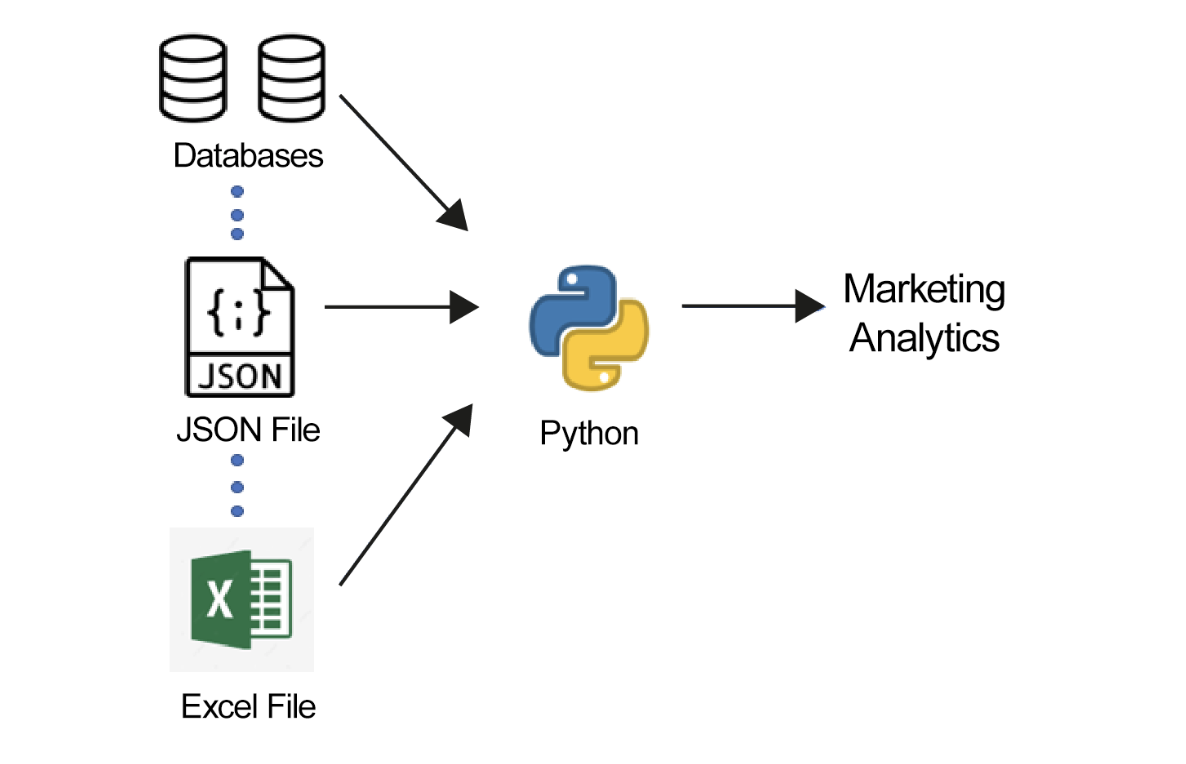 Figura 1.4 - Modelo de datos de la mayoría de los análisis de marketing que utilizan Python
Figura 1.4 - Modelo de datos de la mayoría de los análisis de marketing que utilizan Python
Al utilizar estos scripts que refuerzan la estructura, obtendrá un modelo de datos semiestructurado con los valores esperados en los campos correctos.
Sin embargo, los datos aún no están en el formato óptimo para realizar análisis. Si puede estructurar completamente sus datos (es decir, organizarlos en tablas planas, con el valor correcto apuntando al atributo correcto sin anidación), será fácil ver cómo cada punto de datos se compara individualmente con otros puntos mediante campos comunes.
Puede comprender fácilmente los datos (es decir, ver en qué rango se encuentran la mayoría de los valores, identificar los valores atípicos claros, etc.) simplemente desplazándose por ellos.
Si bien existen muchas herramientas que pueden usarse para convertir datos de un formato no estructurado/semiestructurado a un formato completamente estructurado (por ejemplo, Spark, STATA y SAS), la herramienta más utilizada en ciencia de datos, que se puede integrar con prácticamente cualquier marco de trabajo, tiene funcionalidades avanzadas, costos mínimos y es fácil de usar en nuestro caso práctico, es: